
准备工作
Windows+chromium内核浏览器
因为是谷歌的服务,所以自行配置好网络环境,保正能上谷歌即可。
【注意】断开后Colab将不能运行
提前登录谷歌账号;GitHub账号;GoogleDrive
提前下载
https://huggingface.co/stabilityai/sd-vae-ft-mse-original/blob/main/vae-ft-mse-840000-ema-pruned.ckpt
将其上传至GoogleDrive根目录(最好复制一份作为备份)
收藏并以GitHub登录https://civitai.com/
以便后续使用(开启NSFW,找提示词等)
stable-diffusion_webui使用的是这个项目【以下简称SDwebui】
https://github.com/camenduru/stable-diffusion-webui-colab
个人现在使用的是这个
https://colab.research.google.com/github/camenduru/stable-diffusion-webui-colab/blob/main/stable/stable_diffusion_v2_1_webui_colab.ipynb![图片[1]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/3e7f670826a8b26c40c13.jpg)
准备工作完毕,开始搭建环境
打开colab(上面的那个链接)和civitai![图片[2]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/e9fe97241024df1bb3bce.jpg)
此时应该是这样的,不要着急运行,点左边的文件夹打开![图片[3]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/5e45a496df34108a5564e.jpg)
接着点上面的装载谷歌云端硬盘![图片[4]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/875370560e07df4b52639.jpg)
将滑块(有两层,最外层)拉到最下方,点上移单元格,然后执行![]()
执行后会弹出一个验证,连接到谷歌云盘。
验证后点文件下面的刷新按钮(不是刷新网页)
等待片刻,就会出现drive的目录,将开始上传的VAE拖拽到SD的VAE目录(移动)![图片[6]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/2f46b4a7641efc18c027a.jpg)
最后点击运行这个单元格开始安装相关依赖和程序![图片[7]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/5f9b18e66b90398fc6192.jpg)
经过漫长的等待,最后会生成几个网址,指向本次搭的SD服务![图片[8]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/6ac4f3a1dfd88773922dc.jpg)
[当然是建议https]
开始使用
点开刚生成的任意一个链接(不建议多人使用)![图片[9]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/34b3467c57c34eb2d5429.jpg)
[搭建成功应该是这样]
先加载SD VAE,刚我们从谷歌盘拉过来的那个。![图片[10]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/dc857dbc6bc1c0ce69dc6.jpg)
【注意】没有的话点旁边的刷新
接着我们打开civitai,找个喜欢的模型,比如ChilloutMix,如果你看不到说明没有登录,里面含有NSFW内容,默认是不给显示的。
复制这个名称回到SDwebui,在Civitai按照图示依次完成搜索到下载,注意中间有进度条要等待,开始下载后在colab后台能看到进度。![图片[11]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/36badf4ae723e14f6c800.jpg)
(这个模型看你自己需要来决定是否备份到谷歌云盘,停止程序后可以使用copy命令完成备份,在我看来谷歌盘要快得多)
又是经过漫长的等待,回到SDwebui的主界面,与配置SD VAE一样,载入下载好的主模型(checkpoint)![图片[12]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/c5b3164329e0f875f0604.jpg)
如此一来就可以开始我们的绘图之旅
开始绘图
先熟悉主界面的几个功能![图片[13]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/1fff49be8721c7e2b7498.jpg)
txt2img 文生图
img2img 图生图,好处是有一定的可控性,比如色彩比如构图
image Browser 图片浏览(已经完成的图片)
Extras 通常执行批量ai放大
————————————————————————————————————————————————————————————-
CivitAi 模型站
Hugging Face 需要token,可以直接从上面下开头那个VAE
————————————————————————————————————————————————————————————-
Setting 设置
Extensions 插件
Train 训练
流程:
打开CivitAi找喜欢的模型,载入到SDwebui中,紧接着在模型下方的展示页面里,物色几张好看的图,点入右下角找提示词
将刚刚的Prompt和Negative Prompt填入框中,Prompt为想要的关键词,Negative Prompt为不想要的关键词。![图片[14]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/f4b0d4260f6de67d047d1.jpg)
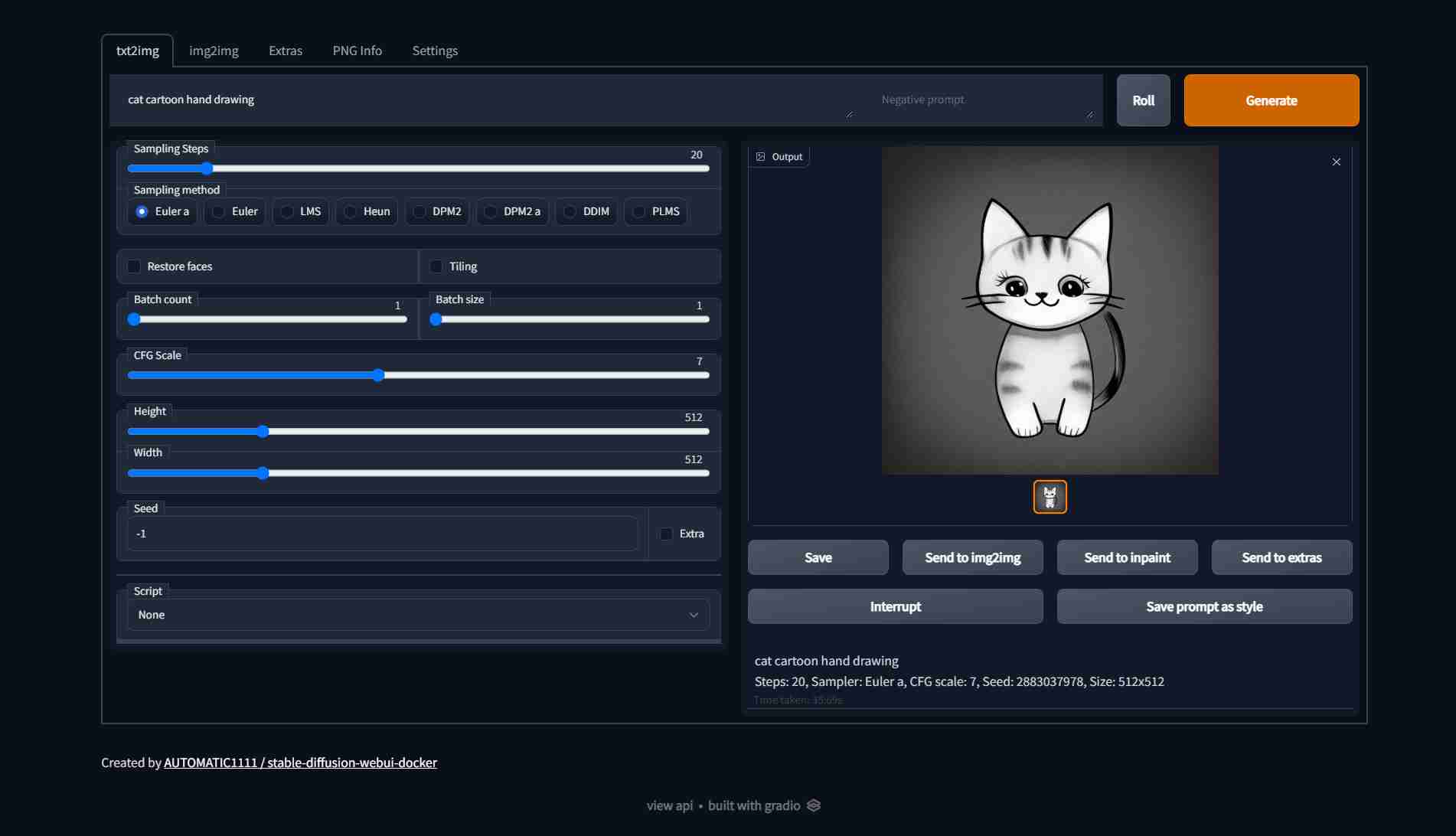
根据需要选择适当的method,steps,CFG以及尺寸。![图片[15]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/567ac6eb36fc04839dc30.jpg)
这里注意尺寸越大速度越慢,并且后续会执行ai放大,建议设置为1500以内,需要快速出图的,请设置在1000以内,并控制步数在20左右。
最后点击generate生成就可以了
同样的,可以在colab后台看到进度![图片[16]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/3def1cb2e75b92ee9d63b.jpg)
完成后,继续点击send to img2img进行放大![图片[17]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/525cc724a71ec80c8713f.jpg)
依次在底部script选择SD upscale,根据需要调整下方的Scale Factor(2即为两倍放大)
Upscaler建议勾选R-ESRGAN 4x+,其余参数请自行尝试。![图片[18]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/5e48ee5ebda980e9ab4d3.jpg)
上方的Denoising strength建议根据模型调整至适当的值,有说法值越高,程序参与改动越多,比如破图。
最后点击生成,等待结果![图片[19]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/878bcf0a8cfbed65e2dd2.png)
【非常重要】过高的尺寸将大幅提升计算时间,甚至造成绘图失败
Lora的使用
简单解释下,一般几种模型可以这么理解:checkpoint为主模型,决定整张图的艺术风格,VAE相当于配色影响图片质感。而Lora则可以当作辅助模型,它可以是雷电将军,也可以是八重樱,可以是奥特曼,也可以是孙悟空,记录了素材的特征,根据这些特征以checkpoint的艺术风格生成图片。
并且Lora是可以自己训练的,难度不高。
同样,我们需要去CivitAi找喜欢的Lora模型,复制名称回到SDwebui,和checkpoint一样,务必在搜索之前勾选Lora![图片[20]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/36ab2b5abcbe82a8c27aa.jpg)
回到主界面,在下方点开Additional Networks,刷新模型,直接第一个模型下拉找到刚下好的Lora(没有说明你没下好),选中后务必勾选Enable。![图片[21]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/5b2e361d2cb57d60e941c.jpg)
如法炮制,仅供参考![图片[22]-stable-diffusion_webui on colab-Stable Diffusion论坛-AI绘图-Khitshu](https://img.722227.xyz/file/34b2ad6d8f8650ea4cc5c.png)
没有回复内容